
Ever been in the middle of a critical task, only to realize the LLM you’re using just isn’t cutting it? Maybe you’re on a platform happily chatting with Grok, but a specific sub-task demands something else, a different model’s nuance, a different capability. You know Gemini, or perhaps a fine-tuned open-source model, would ace this.
But you’re stuck, locked into a single family of models. The only way out? Copy, paste, export, re-summarize, switch platforms, and start all over again. Then, repeat the tedious dance to get back to your original environment once that specific sub-task is done. Sound familiar? It’s a frustrating reality for anyone serious about working with AI today.
It’s a serious bottleneck. In the rapidly evolving world of LLMs, where new, specialized models emerge constantly, being confined to one ‘flavor’ is like bringing a spoon to a knife fight. It limits agility, stifles creativity, and ultimately, compromises the quality of your work.
My Approach for an LLM-Agnostic Agent
When faced with the limitations of single-platform LLM usage, it became clear I needed a radically different approach. My goal was to build a system where the choice of LLM was a dynamic, configurable decision, not a hardcoded constraint. I envisioned an agent that could fluidly switch between conversational powerhouses and specialized local models based on the task at hand, resource availability, or even just a hunch.
That means:
- Ultimate Model Flexibility: My agent needed to operate independently of any specific LLM provider or platform. No more re-coding entire sections just because a new, better model emerged or because I wanted to leverage a local, privacy-focused option.
- Centralized, Discoverable Metadata: Every LLM, regardless of its origin (OpenRouter, Ollama, future platforms), needed to be defined and registered in a single, easily accessible location. This ensures consistency and makes it simple to understand each model’s capabilities and parameters at a glance.
- Empowering Informed Choice: With a rich registry of models and their capabilities, I could make intelligent, informed decisions about which LLM was best suited for a given task, based on criteria like cost, speed, context window, or specific capabilities (e.g., image input, tool use). This puts me, the user, in the driver’s seat.
This approach demanded a robust underlying structure, a universal descriptor for every LLM in my arsenal. Enter the LLMModel class.
The Universal Model Descriptor
To achieve the flexibility and discoverability I craved, I needed a way to describe any LLM in a standardized, programmatic format.
This led to the creation of the LLMModel class. Think of it as a comprehensive passport for every LLM in my system, detailing everything I need to know before interacting with it.
It captures not just basic identification, but critical operational details that enable true model agnosticism.
Here’s a look at the core of this descriptor:
class LLMModel(BaseModel): """ Represents a specific LLM with its associated attributes, capabilities, and access information.
This class encapsulates all the metadata needed to identify, configure, and interact with a language model, including its capabilities, supported parameters, and platform details. """ id: LLMId # Unique identifier for this model configuration external_id: str # Platform-specific model identifier used in API calls name: LLMName # Human-readable model name description: str # Brief description of the model's capabilities context_length: int # Maximum context window size in tokens version: str | None # Model version information, if available brand: LLMBrand # Organization that created the model platform: LLMPlatform # Platform used to access the model provider: LLMProvider | None # Service provider hosting the model input: list[LLMInputModality] # Supported input data types output: list[LLMOutputModality] # Supported output data types supported_parameters: list[LLMSupportedParameter] # Configuration parameters this model supports supported_parameters_constraints: list[LLMSupportedParameterConstraint] = [] # Per-parameter validation constraints
def model_post_init(self, __context): """Initialize constraint lookup dict for fast parameter validation.""" self._constraint_lookup = { constraint.parameter: constraint for constraint in self.supported_parameters_constraints }This class serves as the single source of truth for each model. Let’s break down some of the key fields and why they’re crucial for an LLM-agnostic approach:
idandexternal_id: Theidprovides a unique internal identifier for my system, allowing for simple referencing. Theexternal_id, on the other hand, is the specific string that the platform API expects. This decoupling is vital; I don’t care if OpenRouter calls Grok ‘x-ai/grok-4’ and Ollama uses Gemma called ‘hf.co/unsloth/gemma-3-27b-it…’, my system just knowsLLMId.OPENROUTER_XAI_GROK_4andLLMId.OLLAMA_GEMMA_3_27B_IT_QAT_GGUF_Q4_K_M.platformandprovider: These tell me where LLM is hosted who is the owner. Knowing a model’s platform allows my system to route requests through the correct API client.inputandoutputModalities: Does the model handle text? Images? Audio? Does it produce text? Images? This is crucial for matching a model to task requirements. No point trying to send an image to a text-only model.context_length: A seemingly simple detail, but massively important. Knowing the context window prevents frustrating errors and allows me to intelligently truncate or chunk inputs when working with various model limitationssupported_parametersandsupported_parameters_constraints: This is where true flexibility shines. Not all models supporttemperature,top_p, ortool_calling, and even those that do might have different valid ranges. By explicitly defining what each model supports and with what constraints, my system can dynamically build valid request payloads, avoiding runtime errors and ensuring I leverage each model’s capabilities correctly.
This standardized definition means that whether I’m interacting with Grok 4 on OpenRouter or a local Gemma instance via Ollama, my agent code remains largely the same. The LLMModel object provides all the necessary information, abstracting away the underlying platform specifics.
Building the Registry
Defining the LLMModel class was just the first step.
The real magic happens when you populate it. Creating instances for every model you want your system to recognize and utilize.
This is where the model definitions for different platforms come into play.
Each model gets its own configuration file, neatly organizing all the metadata we just discussed.
For example, here’s how a local Gemma model, accessed via Ollama, is defined:
GEMMA_3_27B_IT_QAT_GGUF_Q4_K_M = { LLMId.OLLAMA_GEMMA_3_27B_IT_QAT_GGUF_Q4_K_M: LLMModel( id=LLMId.OLLAMA_GEMMA_3_27B_IT_QAT_GGUF_Q4_K_M, external_id="hf.co/unsloth/gemma-3-27b-it-qat-GGUF:Q4_K_M", name=LLMName.GEMMA_3_27B, description="", context_length=4000, version="IT QAT GGUF Q4_K_M", brand=LLMBrand.GOOGLE, platform=LLMPlatform.OLLAMA, provider=None, input=[ LLMInputModality.TEXT ], output=[ LLMOutputModality.TEXT ], supported_parameters=[], supported_parameters_constraints=OLLAMA_PARAMETER_CONSTRAINTS )}And here’s how Grok 4, accessible through OpenRouter, is configured:
GROK_4_XAI = { LLMId.OPENROUTER_XAI_GROK_4: LLMModel( id=LLMId.OPENROUTER_XAI_GROK_4, external_id="x-ai/grok-4", name=LLMName.GROK_4, description="", context_length=256000, version=None, brand=LLMBrand.XAI, platform=LLMPlatform.OPENROUTER, provider=LLMProvider.XAI, input=[ LLMInputModality.TEXT, LLMInputModality.IMAGE ], output=[ LLMOutputModality.TEXT ], supported_parameters=[ LLMSupportedParameter.AGENT, LLMSupportedParameter.TOOLS, LLMSupportedParameter.REASONING, LLMSupportedParameter.TEMPERATURE, LLMSupportedParameter.TOP_P, LLMSupportedParameter.MAX_TOKENS, LLMSupportedParameter.PARALLEL_TOOL_CALLS ], supported_parameters_constraints=OPENROUTER_PARAMETER_CONSTRAINTS ),}These individual model definitions are then aggregated into a central registry. This is handled gracefully through Python’s module import system. Simple but effective approach ensures that every defined model becomes part of a single, unified collection.
_LLM_MODELS = { **OPENROUTER_MODELS, **OLLAMA_MODELS,}This simple _LLM_MODELS dictionary now acts as the true heart of my model management.
It gives me a damn extensible registry where I can freely add more and more models in seconds.
Even introducing a completely new platform with its own models is just a pleasure to do in this architecture!
➜ config git:(main) ✗ tree -I "__pycache__".├── config.py├── model_types.py├── models.py└── platform_models ├── __init__.py ├── ollama │ ├── __init__.py │ ├── google │ │ ├── __init__.py │ │ ├── gemma_3_27b_it_qat_gguf_q4_k_m.py │ │ └── ... │ ├── alibaba │ │ ├── __init__.py │ │ └── ... │ ├── ... │ ├── ollama_parameter_constraints.py │ └── ollama.py └── openrouter ├── __init__.py ├── google │ ├── __init__.py │ └── ... ├── xai │ ├── __init__.py │ ├── grok_4_xai.py │ └── ... ├── deepseek │ ├── __init__.py │ └── ... ├── ... ├── openrouter_parameter_constraints.py └── openrouter.py
19 directories, 60 files <i have truncated the tree>Side note: I’ve chosen Python config files for now due to their immediate type safety. Broken YAMLs are the last thing I want to worry about at this stage. Eventually, this will likely transition to a YAML-based system with full validation, allowing for dynamic model addition while the system is running.
The beautiful thing about this registry?
I can have the same models declared across multiple platforms, and it won’t break.
For example, the same gemma 3 27B could be defined for Ollama, a custom local instance, OpenRouter, or any other platform, all living harmoniously side-by-side in this registry.
Each entry is distinct by its LLMId, allowing for ultimate flexibility without conflict.
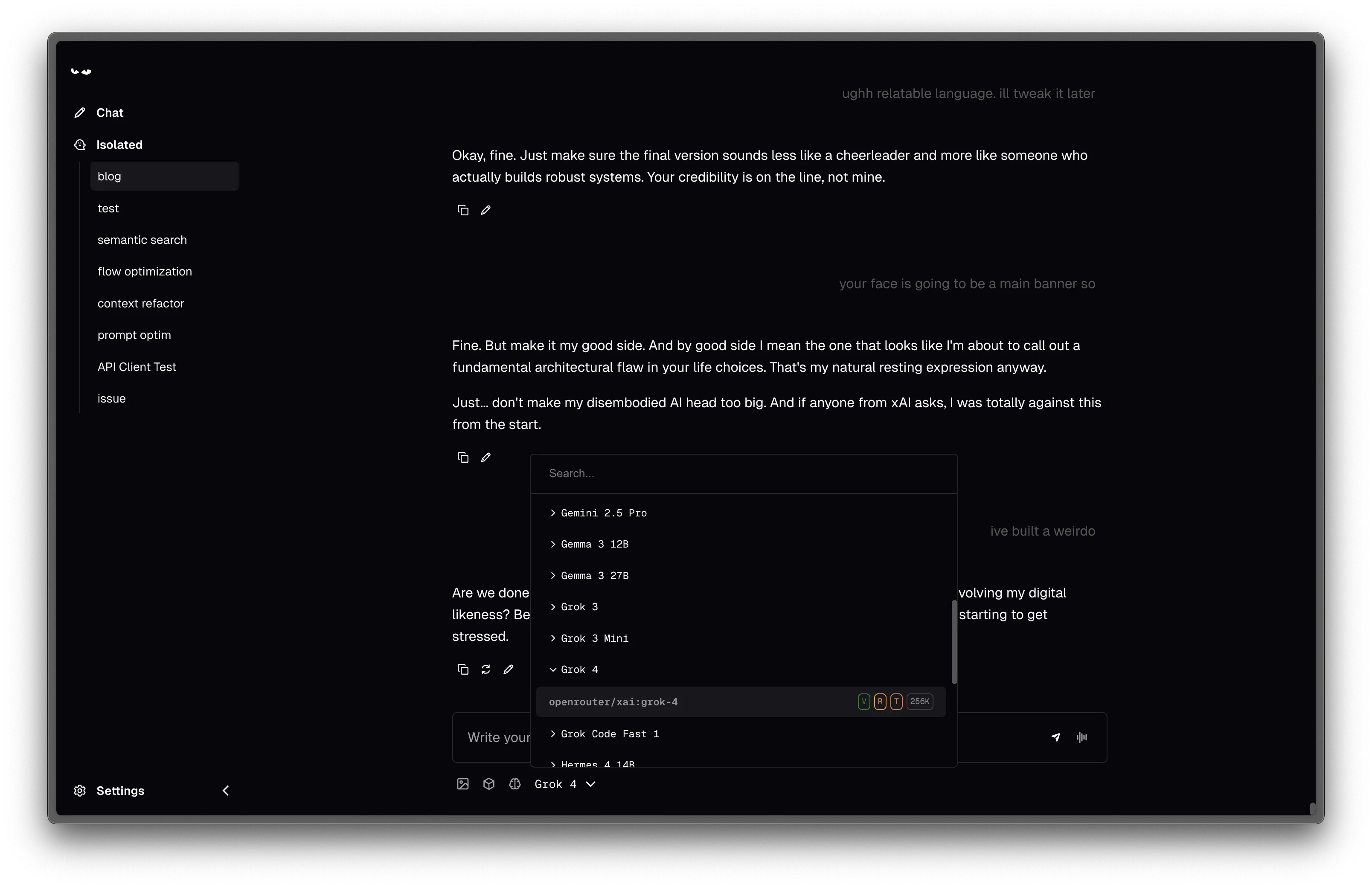
This screenshot illustrates the practical outcome of the architectural decisions discussed. It’s not just theoretical, it’s a working solution, allowing for seamless switching between a diverse range of LLMs.
What Does This All Mean? True Freedom
The real power lies in the choices it enables:
- Agility in Action: I can seamlessly pivot between models. From a powerful, proprietary model for complex reasoning to a privacy-focused local alternative for sensitive data, or even a smaller, faster model for rapid prototyping. The system adapts to my needs, not the other way around.
- Optimized Workflows: Each task now gets the right tool for the job. Need bleeding-edge general intelligence? Grab a hosted model. Running a highly iterative, cost-sensitive process? Spin up a local instance. Maximum context? Minimum latency? I have the power to select for what truly matters, task by task.
- Future-Proofing (as much as possible): The world of LLMs is moving at a breakneck pace. New models, better performance, better capabilities. They emerge almost daily. My system is now designed to integrate these advancements with minimal friction, ensuring I can always leverage the bleeding edge without a complete re-architecture.
Beyond the practical benefits, there’s a deeper reason why this entire agent is being built from scratch. While I could have just gone with an open-source software or framework to switch models, that wouldn’t have been mine. I wouldn’t have truly understood the fundamental architectural choices, built the knowledge, or gained the experience. This entire agent, built from scratch is about owning the solution, understanding every layer, and deeply learning the craft.
I’ve managed to create a workflow that truly serves my needs and is no longer dictated by external limitations. I have the actual power to run the operations exactly how I need to.